予測が低いから作る、ではない。どれくらい危ないかを見て作る。
本章では、ガウス過程回帰(GPR)を導入し、予測値 \(\mu\) だけでなく 予測の不確かさ \(\sigma\) を活用する方法を学ぶ。そして、\(\mu\) と \(\sigma\) を組み合わせた候補選定(UCB スコア)まで進む。
5.1 なぜ「値」だけでは足りないのか
次の3つの候補を考えてみよ。
A
\(-40\) \(5\)
B
\(-55\) \(25\)
C
\(-30\) \(3\)
\(\Delta_1\) を小さくしたい場合、予測平均だけで選ぶなら B が最有力である。しかし B は \(\sigma\) が大きく、実際には \(-55 \pm 25\) K の範囲、つまり \(-80\) K から \(-30\) K まで振れうる。一方、A は \(-40 \pm 5\) K であり、ほぼ確実に \(-45\) K 〜 \(-35\) K の範囲に収まる。
研究費と時間が限られているとき、B に「賭ける」のか、A で「手堅く行く」のかは、予測値だけでは判断できない。不確かさを読む能力 が必要である。
5.2 GPR を式ではなく絵で理解する
GPR(Gaussian Process Regression)の数学的な導出は本書の範囲外である。ここでは、直感的に以下の3点だけを押さえる。
近い特徴量の点は、似た物性を持ちやすい と仮定するその「似ていそう」をなめらかにつないで予測する
学習データの近くでは自信が出やすく、遠いと自信が下がる
比喩で言えば、GPR は「観測点をなめらかにつなぐ地形図」のようなものである。観測点が密な場所は等高線が正確に描けるが、観測点がない場所は大きな不確かさを伴う。
論文では、カーネルとして定数項 × Matérn(\(\nu = 1.5\) )+ White ノイズを使っている。Matérn カーネルは「なめらかだが少し粗さも許す」性質を持ち、White カーネルは「測定ノイズや表現しきれない揺らぎ」を吸収する。
5.3 1次元 GPR を体感する
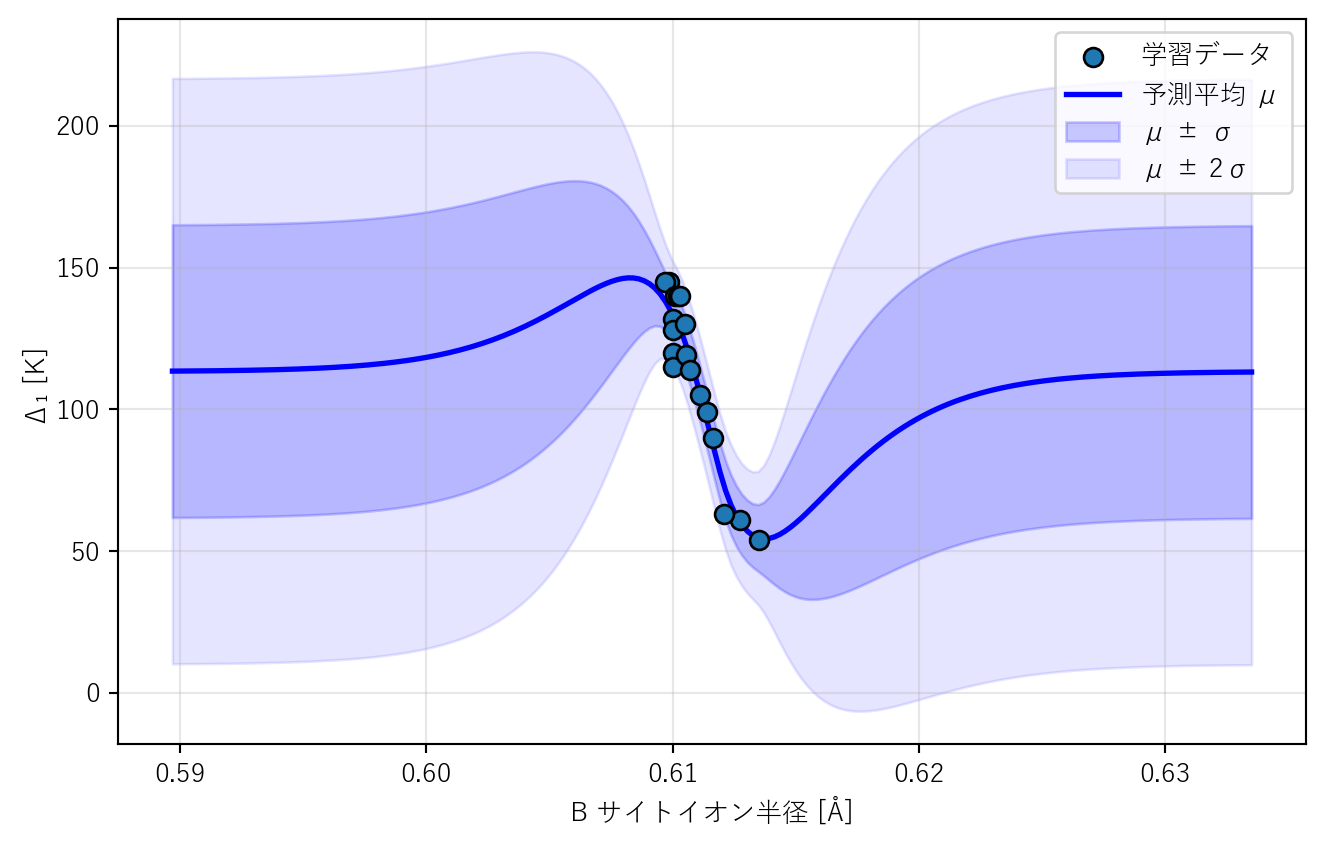
まずは B サイト半径だけの1次元 GPR を可視化する。この段階の目的は性能評価ではなく、GPR の見え方に慣れること である。
コード
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.gaussian_process import GaussianProcessRegressorfrom sklearn.gaussian_process.kernels import (as Cimport matplotlib.font_manager as fmfor _font in ['Yu Gothic' , 'Hiragino Sans' , 'IPAexGothic' , 'Noto Sans CJK JP' ]:if any (f.name == _font for f in fm.fontManager.ttflist):'font.family' ] = _fontbreak 'axes.unicode_minus' ] = False = pd.read_csv("data/feature_site_split_full.csv" )= df[["B_Ion_Radius" ]].values= df["delta_1" ].values
コード
# GPR を fit = C(1.0 ) * Matern(nu= 1.5 , length_scale= 1.0 ) + WhiteKernel(noise_level= 1e-2 )= GaussianProcessRegressor(= kernel,= 5 ,= 0.005 ,= True ,= 42 ,# 予測グリッド = np.linspace(X_rb.min () - 0.02 , X_rb.max () + 0.02 , 200 ).reshape(- 1 , 1 )= gpr_1d.predict(x_grid, return_std= True )= plt.subplots(figsize= (7 , 4.5 ))= 50 , edgecolors= "k" , zorder= 3 , label= "学習データ" )"b-" , linewidth= 2 , label= "予測平均 μ" )- sigma, mu + sigma,= 0.2 , color= "blue" , label= "μ ± σ" - 2 * sigma, mu + 2 * sigma,= 0.1 , color= "blue" , label= "μ ± 2σ" "B サイトイオン半径 [Å]" )"Δ₁ [K]" )= "upper right" )True , alpha= 0.3 )
学習データの密な領域と疎な領域で、\(\sigma\) の帯幅はどう違うか
グラフの両端(データ範囲の外)で帯はどうなっているか
前章の線形回帰と比べて、GPR が追加で与える情報は何か
学習データが密な領域では \(\sigma\) が小さく、帯が狭い。疎な領域では \(\sigma\) が大きく、帯が広い
データ範囲の外では帯が急激に広がる。GPR は学習データの外側に対して自信を持てない
線形回帰は予測値を1つの数字として返すだけだが、GPR は「予測値」と「その予測をどれだけ信用してよいか」を同時に返す
5.4 交差検証つき GPR
性能評価には、前章と同じく 3-fold CV を使う。GPR では predict(X, return_std=True) で \(\mu\) と \(\sigma\) を同時に取得できる。
コード
from sklearn.model_selection import KFoldfrom sklearn.metrics import mean_squared_error, r2_scorefrom sklearn.preprocessing import StandardScalerfrom sklearn.impute import SimpleImputer= [c for c in df.columns if c not in ["composition" , "delta_1" ]]= df[feat_cols].values= df["delta_1" ].valuesdef make_gpr():"""論文と同じカーネル構成の GPR を返す""" = C(1.0 ) * Matern(nu= 1.5 , length_scale= 1.0 ) + WhiteKernel(noise_level= 1e-2 )return GaussianProcessRegressor(= kernel,= 5 ,= 0.005 ,= True ,= 42 ,# 3-fold CV(前処理は fold 内で fit) = KFold(n_splits= 3 , shuffle= True , random_state= 42 )= []for fold_i, (train_idx, test_idx) in enumerate (cv.split(X_all)):= X_all[train_idx], X_all[test_idx]= y_all[train_idx], y_all[test_idx]# 前処理(training fold のみで fit) = SimpleImputer(strategy= "mean" ).fit(X_tr)= StandardScaler().fit(imp.transform(X_tr))= scaler.transform(imp.transform(X_tr))= scaler.transform(imp.transform(X_te))# GPR を学習・予測 = make_gpr()= gpr.predict(X_te_s, return_std= True )= np.sqrt(mean_squared_error(y_te, mu_te))= r2_score(y_te, mu_te)for j in range (len (y_te)):"fold" : fold_i + 1 ,"composition" : df.iloc[test_idx[j]]["composition" ],"実測" : y_te[j],"予測μ" : round (mu_te[j], 1 ),"σ" : round (sigma_te[j], 1 ),"|誤差|" : round (abs (y_te[j] - mu_te[j]), 1 ),print (f"Fold { fold_i+ 1 } : RMSE = { rmse:.1f} K, R² = { r2:.3f} " )= pd.DataFrame(fold_results)
Fold 1: RMSE = 6.0 K, R² = 0.955
Fold 2: RMSE = 7.5 K, R² = 0.927
Fold 3: RMSE = 3.6 K, R² = 0.966
C:\Users\satok\miniconda3\envs\sci\Lib\site-packages\sklearn\gaussian_process\kernels.py:440: ConvergenceWarning:
The optimal value found for dimension 0 of parameter k2__noise_level is close to the specified lower bound 1e-05. Decreasing the bound and calling fit again may find a better value.
0
1
LaCoO3
132
140.1
2.4
8.1
1
1
La0.99Sr0.01CoO3
128
125.4
24.0
2.6
2
1
La0.97Sr0.03CoO3
115
114.6
28.7
0.4
3
1
LaCo0.996Al0.004O3
145
147.2
3.0
2.2
4
1
LaCo0.97Ga0.03O3
140
137.4
4.2
2.6
5
1
LaCo0.95Rh0.05O3
61
72.5
16.2
11.5
6
2
La0.98Sr0.02CoO3
120
120.9
5.1
0.9
7
2
LaCo0.95Ga0.05O3
130
139.9
9.8
9.9
8
2
LaCo0.98Rh0.02O3
105
104.4
3.5
0.6
9
2
LaCo0.98Ir0.02O3
99
94.2
6.5
4.8
10
2
LaCo0.97Ir0.03O3
63
76.2
10.9
13.2
11
2
LaCo0.95Ir0.05O3
54
47.4
22.0
6.6
12
3
LaCo0.998Al0.002O3
145
138.1
6.2
6.9
13
3
LaCo0.99Ga0.01O3
140
138.4
6.5
1.6
14
3
LaCo0.98Ga0.02O3
140
139.2
6.8
0.8
15
3
LaCo0.99Rh0.01O3
119
121.9
6.7
2.9
16
3
LaCo0.97Rh0.03O3
90
87.2
7.6
2.8
17
3
LaCo0.99Ir0.01O3
114
117.0
7.0
3.0
上の表で、\(\sigma\) が大きい組成と |誤差| が大きい組成は一致しているか。一致していない場合、\(\sigma\) は何を意味しているのか。
\(\sigma\) と |誤差| は必ずしも一致しない。\(\sigma\) はモデルが「この予測に自信を持ちにくい」という内部的な指標であり、実際の予測誤差(= |\(y\) − \(\mu\) |)そのものではない。\(\sigma\) が大きくても偶然正確に当たることもあるし、\(\sigma\) が小さくても系統的に外れることもある。\(\sigma\) は「警告信号」として使うべきであり、「保証」として使うべきではない。
ここで \(\sigma\) の物理的な妥当性を確認する。上の表で \(\sigma\) は多くの点で 5–15 K に収まっている。\(\Delta_1\) の観測範囲(約 45–480 K)に対して 1–3% 程度であり、モデルは学習データの近傍では十分な自信を持てていると言える。一方、候補スクリーニング(5.6 節)では学習データから遠い候補ほど \(\sigma\) が大きくなり、\(\sigma \geq 30\) K(全範囲の約 7%)を OOD 警告の目安とする。
なお、4.2 節の DummyRegressor(全組成の平均を常に予測、R² = 0)に対して、GPR は RMSE を大幅に改善している。GPR が線形回帰に対して追加で与えるのは、予測値だけでなく各データ点の \(\sigma\) を同時に得られる点である。
\(\sigma\) は予測誤差そのものではなく、モデルが自信を持ちにくい度合いを示す指標である。
5.5 物理ベースライン+残差 GPR
論文では、いきなり全特徴量を GPR に任せていない。まず 有効 B サイト半径 \(r_B\) に対する単調減少ベースライン \(f_{\mathrm{phys}}(r_B)\) を作り、その残差
\[y_{\mathrm{res}} = \Delta_1 - f_{\mathrm{phys}}(r_B)\]
を GPR で学習する。この構成を Δ-learning (デルタラーニング)と呼ぶ。
コード
from sklearn.isotonic import IsotonicRegressiondef fit_baseline_and_residual_gpr(X_tr, y_tr, r_B_tr, X_te, r_B_te):"""単調ベースライン + 残差 GPR(fold 内で完結)""" # 1. 単調ベースライン(training fold のみで fit) = IsotonicRegression(increasing= False , out_of_bounds= "clip" )= iso.predict(r_B_tr)= iso.predict(r_B_te)# 2. 残差を計算 = y_tr - baseline_tr# 3. 前処理(training fold のみで fit) = SimpleImputer(strategy= "mean" ).fit(X_tr)= StandardScaler().fit(imp.transform(X_tr))= scaler.transform(imp.transform(X_tr))= scaler.transform(imp.transform(X_te))# 4. 残差 GPR = make_gpr()= gpr.predict(X_te_s, return_std= True )# 5. 最終予測 = ベースライン + 残差予測 = baseline_te + mu_res= sigma_resreturn mu_final, sigma_final
コード
# 残差 GPR の 3-fold CV = df["B_Ion_Radius" ].values= KFold(n_splits= 3 , shuffle= True , random_state= 42 )= []for fold_i, (train_idx, test_idx) in enumerate (cv.split(X_all)):= X_all[train_idx], X_all[test_idx]= y_all[train_idx], y_all[test_idx]= r_B[train_idx], r_B[test_idx]= fit_baseline_and_residual_gpr(= np.sqrt(mean_squared_error(y_te, mu_te))= r2_score(y_te, mu_te)for j in range (len (y_te)):"fold" : fold_i + 1 ,"composition" : df.iloc[test_idx[j]]["composition" ],"実測" : y_te[j],"予測μ" : round (mu_te[j], 1 ),"σ" : round (sigma_te[j], 1 ),"|誤差|" : round (abs (y_te[j] - mu_te[j]), 1 ),print (f"Fold { fold_i+ 1 } : RMSE = { rmse:.1f} K, R² = { r2:.3f} " )= pd.DataFrame(residual_results)
Fold 1: RMSE = 6.0 K, R² = 0.954
Fold 2: RMSE = 7.1 K, R² = 0.935
Fold 3: RMSE = 7.3 K, R² = 0.858
C:\Users\satok\miniconda3\envs\sci\Lib\site-packages\sklearn\gaussian_process\kernels.py:440: ConvergenceWarning:
The optimal value found for dimension 0 of parameter k2__noise_level is close to the specified lower bound 1e-05. Decreasing the bound and calling fit again may find a better value.
0
1
LaCoO3
132
135.0
2.1
3.0
1
1
La0.99Sr0.01CoO3
128
129.6
5.6
1.6
2
1
La0.97Sr0.03CoO3
115
128.6
6.1
13.6
3
1
LaCo0.996Al0.004O3
145
147.4
2.2
2.4
4
1
LaCo0.97Ga0.03O3
140
136.9
2.4
3.1
5
1
LaCo0.95Rh0.05O3
61
58.7
4.5
2.3
6
2
La0.98Sr0.02CoO3
120
121.1
4.9
1.1
7
2
LaCo0.95Ga0.05O3
130
126.6
6.0
3.4
8
2
LaCo0.98Rh0.02O3
105
104.1
1.9
0.9
9
2
LaCo0.98Ir0.02O3
99
96.8
4.3
2.2
10
2
LaCo0.97Ir0.03O3
63
78.4
6.8
15.4
11
2
LaCo0.95Ir0.05O3
54
61.0
8.5
7.0
12
3
LaCo0.998Al0.002O3
145
139.2
3.9
5.8
13
3
LaCo0.99Ga0.01O3
140
131.2
3.9
8.8
14
3
LaCo0.98Ga0.02O3
140
132.1
3.9
7.9
15
3
LaCo0.99Rh0.01O3
119
127.9
3.9
8.9
16
3
LaCo0.97Rh0.03O3
90
87.0
4.0
3.0
17
3
LaCo0.99Ir0.01O3
114
121.6
3.9
7.6
論文では、残差 GPR(Δ-learning)の 3-fold CV で RMSE = 7.21 ± 1.18 K, R² = 0.907 ± 0.049 を報告している。上の結果と近い値が得られれば、論文の再現ができたと言える。
直接 GPR(5.4 節)と残差 GPR(5.5 節)で、RMSE はどう変化したか
なぜ物理ベースラインを入れると改善するのか、1〜2文で説明せよ
この簡略版コードでは残差 GPR が直接 GPR より必ずしも RMSE を改善するとは限らない。Isotonic ベースラインを全 18 組成(A サイト置換の Sr 系を含む)に対して一括 fit しているためである。論文準拠の実装では、ベースラインの fit を B サイト系列に寄せた設計になっており、そこでは残差 GPR の改善が見られる
原理的には、物理ベースラインが「半径が大きいほど \(\Delta_1\) が下がる」という大まかな傾向を先に吸収するため、GPR が学ぶべき残差が小さくなり、少ないデータでも精度の高い予測が期待できる。物理の知識でモデルの負担を減らす設計思想である
ここまでの構造を三段階で整理する。まず、IsotonicRegression で「半径が大きいほど \(\Delta_1\) は下がる」という物理的傾向をベースラインとして吸収する。次に、ベースラインでは捉えきれない残差を GPR で学習し、予測値 \(\mu\) と予測標準偏差 \(\sigma\) を同時に得る。以上より、物理の知識でモデルの負担を減らしつつ、不確かさを定量する設計が成立する。ただし、この簡略版ではベースラインの設計が論文ほど精緻でないため、改善幅はデータの分割やベースラインの扱いに依存する点に注意が必要である。
5.6 候補スクリーニング:\(\mu + \kappa\sigma\) で選ぶ
いよいよ、\(\mu\) と \(\sigma\) を使って未知候補を評価する。
論文では、OS=3, CN=6 を満たす 39 元素を対象に全候補スクリーニングを行っている。以下ではその手順を、学習用に 5 元素(Al, Ga, Rh, Ir, Y)に限定した簡略版で再現する。
全18組成で最終モデル(ベースライン + GPR)を学習する
候補元素に対して \(\mu\) と \(\sigma\) を予測する
UCB スコア = \(\mu + \kappa\sigma\) (\(\kappa = 1.0\) )を計算するスコアの小さい順に並べる(\(\Delta_1\) を小さくしたいため)
\(\sigma \geq 30\) K の候補には「学習範囲外」警告を付ける
\(\kappa\) は「不確かさをどれだけ重視するか」の調整パラメータである。\(\kappa = 0\) なら平均だけで選ぶ(攻めの選定)、\(\kappa > 0\) なら不確かさも加味する(慎重な選定)。
コード
# 全学習データで最終モデルを fit = IsotonicRegression(increasing= False , out_of_bounds= "clip" )= y_all - iso_full.predict(r_B)= SimpleImputer(strategy= "mean" ).fit(X_all)= StandardScaler().fit(imp_full.transform(X_all))= scaler_full.transform(imp_full.transform(X_all))= make_gpr()print ("最終モデルの学習が完了した" )
コード
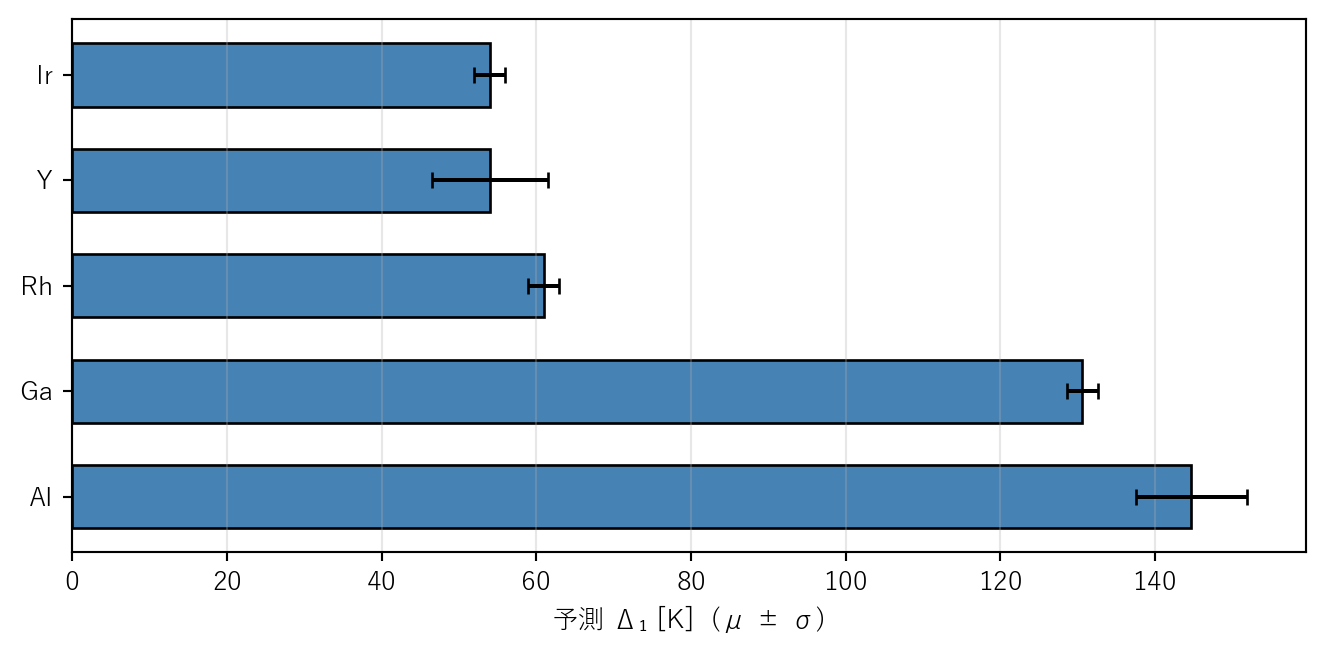
# 候補データの構築: 記述子辞書から OS=3, CN=6 の B サイト候補を取得 = pd.read_csv("data/descriptor_selected.csv" )= desc.set_index(["element" , "OS" , "CN" ])= ["Ion_Radius" , "IonizationPotential_eV_" ,"ElectronAffinity_eV_" , "Electronegativity" ]# Y を候補として評価する(LaCo₀.₉₅Y₀.₀₅O₃) = 0.05 def make_candidate_features(dopant_element, x_B= 0.05 ):"""候補元素について、x_B での特徴量ベクトルを作る""" = {}for key in keys:# A サイト: La のみ(x_A = 0) f"A_ { key} " ] = desc_idx.loc[("La" , 3 , 12 ), key]# B サイト: (1-x_B)*Co + x_B*M = desc_idx.loc[("Co" , 3 , 6 ), key]= desc_idx.loc[(dopant_element, 3 , 6 ), key]f"B_ { key} " ] = (1 - x_B) * co_val + x_B * m_valreturn feats# 記述子辞書にある OS=3, CN=6 の候補元素 = ["Al" , "Ga" , "Rh" , "Ir" , "Y" ]= []for elem in candidates:= make_candidate_features(elem, x_B= x_screen)= feats["B_Ion_Radius" ]# ベースライン予測 = iso_full.predict([r_B_cand])[0 ]# 残差 GPR 予測 = np.array([[feats[f"A_ { k} " ] for k in keys] + f"B_ { k} " ] for k in keys]])= scaler_full.transform(imp_full.transform(X_cand))= gpr_full.predict(X_cand_s, return_std= True )= baseline_cand + mu_res[0 ]= sigma_res[0 ]= 1.0 = mu_final + kappa * sigma_final"元素" : elem,"r_B" : round (r_B_cand, 4 ),"μ [K]" : round (mu_final, 1 ),"σ [K]" : round (sigma_final, 1 ),f"μ+ { kappa} σ [K]" : round (score, 1 ),"OOD警告" : "⚠" if sigma_final >= 30 else "" ,= pd.DataFrame(cand_rows).sort_values(f"μ+ { kappa} σ [K]" )
3
Ir
0.6135
54.0
2.0
56.0
4
Y
0.6245
54.0
7.5
61.5
2
Rh
0.6128
61.0
2.0
63.0
1
Ga
0.6105
130.6
2.0
132.6
0
Al
0.6063
144.7
7.2
151.9
予測平均 \(\mu\) だけで選ぶと、上位はどの元素か
UCB スコア \(\mu + \sigma\) で選ぶと、順位はどう変わるか
研究費が限られているとき、あなたはどの候補を「最初に合成する」か。理由も述べよ
\(\mu\) が最も低い元素が上位になる。Ir や Rh は \(\mu\) が低い傾向がある\(\sigma\) が大きい元素はスコアが上がり(=悪化し)、順位が下がる。逆に \(\sigma\) が小さい元素は安定して上位に留まる。Y は \(\mu\) が中程度でも \(\sigma\) が適度に小さいため、UCB では上位に来る可能性がある堅実に進めるなら \(\sigma\) が小さく \(\mu + \sigma\) が低い候補を選ぶ。リスクを取って新規性を狙うなら \(\mu\) が非常に低いがσが大きい候補を選ぶ。実験コストも考慮すると、まず堅実候補から始めるのが合理的である
コード
= plt.subplots(figsize= (7 , 3.5 ))= cand_df.sort_values("μ+1.0σ [K]" )= range (len (cand_sorted))"μ [K]" ], xerr= cand_sorted["σ [K]" ],= 0.6 , color= "steelblue" , edgecolor= "k" , capsize= 3 )"元素" ])"予測 Δ₁ [K] (μ ± σ)" )True , alpha= 0.3 , axis= "x" )
5.7 安全な候補と挑戦的な候補
同じ予測結果でも、候補の選び方は文脈で変わる。
研究費・時間が限られている
堅実候補(\(\mu + \sigma\) が小さい)
新規性を重視する
挑戦候補(\(\mu\) が非常に低いが \(\sigma\) も大きい)
学生実験で使いたい
安全候補(\(\sigma\) が小さく合成しやすい)
論文化を急ぎたい
既存データとの整合性が高い候補
論文が Y を選んだのは、「予測平均が低い」だけでなく、「不確かさを含めても実行可能な候補」であったからである。Y は従来の遷移金属ドーパント(Al, Ga, Rh, Ir)とは異なる希土類元素であり、非直感的な候補でありながら、スクリーニングで浮上した点に研究の価値がある。
\(\sigma\) はモデルの内部的な不確かさであり、以下のリスクは反映しない。
記述子辞書にない物理効果(電荷移動、磁気相互作用等)
学習データの系統的偏り
実験の合成困難性
\(\sigma\) は「モデルの自信のなさ」であって、「実験の成功確率」ではない。
\(\sigma\) は予測誤差そのものではなく、モデルが自信を持ちにくい度合いを示す指標である。未知候補に向かうとき、予測値だけでなく不確かさを含めて判断する——これが、小標本の材料探索における研究態度の核心である。
章末演習
演習 5-1 GPR の出力を「平均 \(\mu\) 」と「標準偏差 \(\sigma\) 」の2つに分けて、それぞれが何を表すかを各1文で説明せよ。
演習 5-2 \(\sigma\) が大きい候補を実験に選ぶことのメリットとデメリットを、それぞれ1〜2文で述べよ。
演習 5-3 \(\kappa = 0\) (平均のみ)と \(\kappa = 2\) (不確かさ重視)で候補ランキングを作り直し、上位3元素がどう変わるかを表にまとめよ。
演習 5-4 線形回帰ではなく GPR を使うことで「増える」ものは何か。150字以内で説明せよ。