予測する前に見る。見えた気になる前に、評価を確かめる。
本章では、前章で作った特徴量テーブルを使い、単純な回帰モデルで \(\Delta_1\) を予測する。ここでの目標は高精度の予測ではなく、「予測とは何か」「評価とは何か」「やってはいけないことは何か」 を体得することである。
この章を読み終えたとき、以下の4つができることが目標である。
散布図と相関から、効きそうな特徴量を見抜ける
単回帰・多変量回帰を組んで、性能指標(RMSE, R²)を計算できる
交差検証(CV)の必要性を、split の不安定さから説明できる
データリークの典型例を見つけて修正できる
4.1 見ることから始める
モデルを組む前に、データを見る。これは材料 ML に限らず、あらゆるデータ分析の鉄則である。
コード
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.font_manager as fmfor _font in ['Yu Gothic' , 'Hiragino Sans' , 'IPAexGothic' , 'Noto Sans CJK JP' ]:if any (f.name == _font for f in fm.fontManager.ttflist):'font.family' ] = _fontbreak 'axes.unicode_minus' ] = False # 全18組成のフル特徴量テーブルを読み込む = pd.read_csv("data/feature_site_split_full.csv" )print (f"形状: { df. shape} " )
0
LaCoO3
132
1.3600
5.577000
0.5000
1.1000
0.61000
7.88100
0.66000
1.88000
1
La0.99Sr0.01CoO3
128
1.3608
5.578178
0.4961
1.0985
0.61000
7.88100
0.66000
1.88000
2
La0.98Sr0.02CoO3
120
1.3616
5.579356
0.4922
1.0970
0.61000
7.88100
0.66000
1.88000
3
La0.97Sr0.03CoO3
115
1.3624
5.580534
0.4883
1.0955
0.61000
7.88100
0.66000
1.88000
4
LaCo0.998Al0.002O3
145
1.3600
5.577000
0.5000
1.1000
0.60985
7.87721
0.65956
1.87946
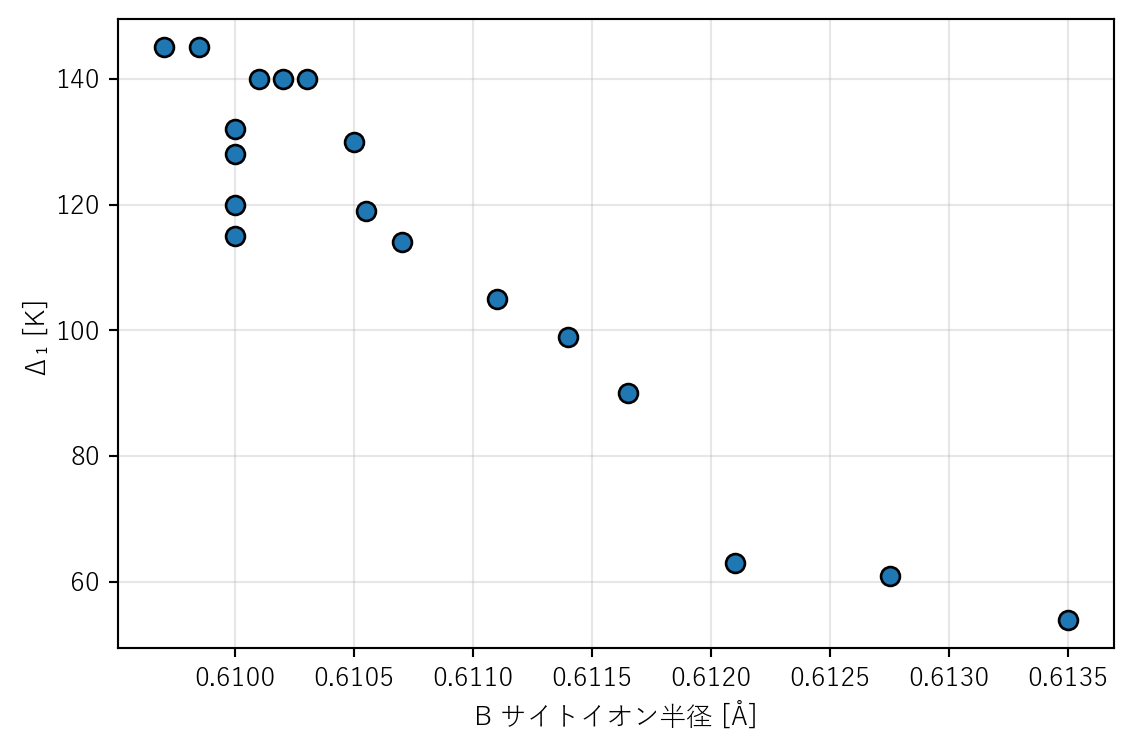
まず、B サイトイオン半径 vs \(\Delta_1\) の散布図を描く。
コード
= plt.subplots(figsize= (6 , 4 ))"B_Ion_Radius" ], df["delta_1" ], s= 50 , edgecolors= "k" , zorder= 3 )"B サイトイオン半径 [Å]" )"Δ₁ [K]" )True , alpha= 0.3 )
全体として右上がりか、右下がりか
B_Ion_Radius が同じ値で \(\Delta_1\) が異なる点がある。それはどの組成か。なぜそうなるか
直線で十分か、やや曲がっていそうか
全体として右下がりの傾向がある。B サイト半径が大きくなるほど \(\Delta_1\) は小さくなる
LaCoO₃ と Sr 系の3組成である。いずれも B サイト置換がないため B_Ion_Radius は Co³⁺ の値で同じだが、A サイトの Sr 置換によって \(\Delta_1\) が変化している。つまり、B サイト半径だけでは Sr 系の変化を説明できない
やや曲がっている。特に低半径(純 Co)側でのばらつきと、高半径(Ir, Rh 系)側での急な減少が見える
次に、全特徴量の相関係数を確認する。
コード
= [c for c in df.columns if c not in ["composition" , "delta_1" ]]= df[feat_cols + ["delta_1" ]].corr()["delta_1" ].drop("delta_1" ).sort_values()print ("delta_1 との相関係数:" )print (corr.to_string())
delta_1 との相関係数:
B_Ion_Radius -0.946578
B_Electronegativity -0.925010
B_ElectronAffinity_eV_ -0.906598
B_IonizationPotential_eV_ -0.550382
A_Electronegativity -0.078646
A_ElectronAffinity_eV_ -0.078646
A_Ion_Radius 0.078646
A_IonizationPotential_eV_ 0.078646
相関が高い特徴量は予測に有用だが、「相関が高い = 原因」ではない。B_Ion_Radius と \(\Delta_1\) の負の相関は、半径が大きいイオンほど \(\Delta_1\) を下げる因果関係を示唆するが、それだけでは証明にはならない。因果の議論には実験検証が必要であり、それが第6章の主題である。
4.2 基準線:平均値予測
モデルの性能を「良い」「悪い」と判断するには、比較基準が必要である。最も単純な基準は、常に \(\Delta_1\) の平均値を予測するモデル である。
コード
from sklearn.dummy import DummyRegressorfrom sklearn.metrics import mean_squared_error, r2_score= df[feat_cols].values= df["delta_1" ].values= DummyRegressor(strategy= "mean" )= dummy.predict(X)= np.sqrt(mean_squared_error(y, y_pred_dummy))= r2_score(y, y_pred_dummy)print (f"平均値予測: RMSE = { rmse_dummy:.1f} K, R² = { r2_dummy:.4f} " )print (f"(全組成の平均 Δ₁ = { y. mean():.1f} K)" )
平均値予測: RMSE = 28.6 K, R² = 0.0000
(全組成の平均 Δ₁ = 113.3 K)
R² = 0 は「平均を答えるだけ」と同等であることを意味する。これを下回るモデルは、何もしないより悪い。
4.3 半径1変数の単回帰
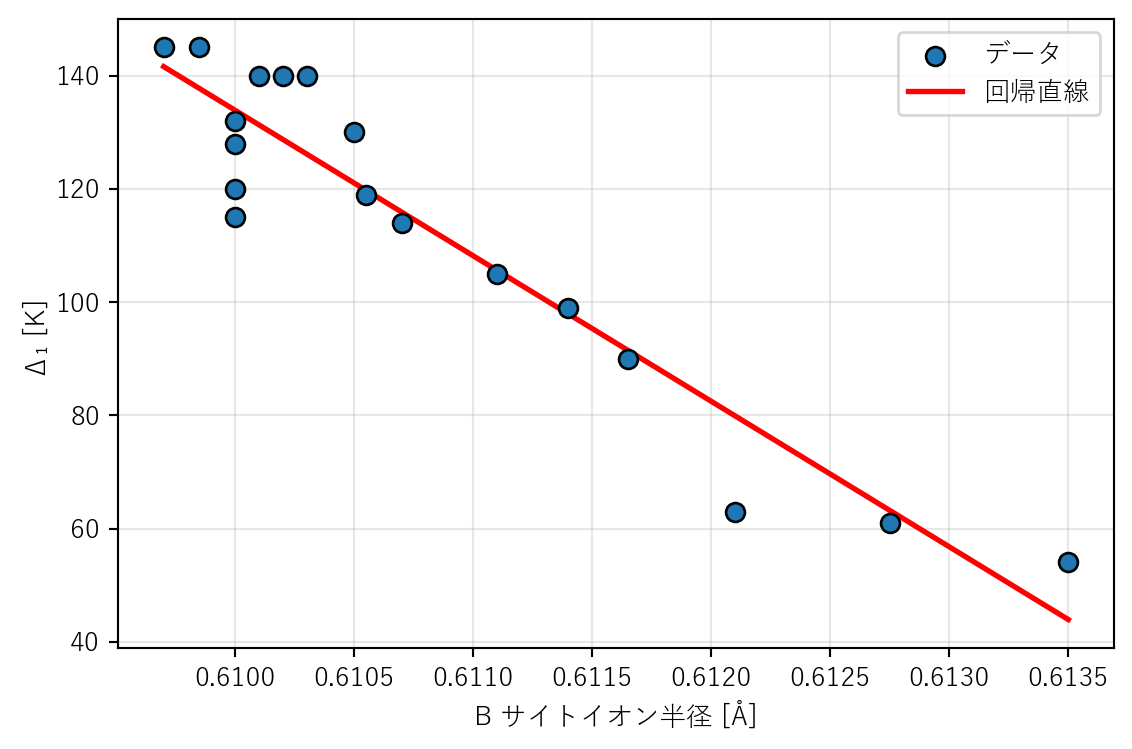
まずは B サイト半径だけで回帰する。最初に、全データで線を引いて様子を見る。
コード
from sklearn.linear_model import LinearRegression= df[["B_Ion_Radius" ]].values= LinearRegression()= model_r.predict(X_r)= np.sqrt(mean_squared_error(y, y_pred_r))= r2_score(y, y_pred_r)print (f"全データ fit: RMSE = { rmse_full:.1f} K, R² = { r2_full:.3f} " )
全データ fit: RMSE = 9.2 K, R² = 0.896
コード
= plt.subplots(figsize= (6 , 4 ))"B_Ion_Radius" ], y, s= 50 , edgecolors= "k" , zorder= 3 , label= "データ" )= np.linspace(X_r.min (), X_r.max (), 100 ).reshape(- 1 , 1 )"r-" , linewidth= 2 , label= "回帰直線" )"B サイトイオン半径 [Å]" )"Δ₁ [K]" )True , alpha= 0.3 )
この図は「説明図」としてはよいが、性能評価ではない 。学習に使ったデータで予測しているため、未知データへの汎化性能は分からない。
train/test split で評価する
コード
from sklearn.model_selection import train_test_split= train_test_split(= 0.33 , random_state= 42 = LinearRegression()= model_split.predict(X_test)= np.sqrt(mean_squared_error(y_test, y_pred_test))= r2_score(y_test, y_pred_test)print (f"test RMSE = { rmse_test:.1f} K, R² = { r2_test:.3f} " )print (f"test サンプル数: { len (y_test)} " )
test RMSE = 10.4 K, R² = 0.863
test サンプル数: 6
RMSE は「だいたい何 K ずれるか」、R² は「平均予測と比べてどれだけ改善したか」を表す。材料系では RMSE の方が物理量として直感的であり、まずこちらで性能感覚をつかむとよい。
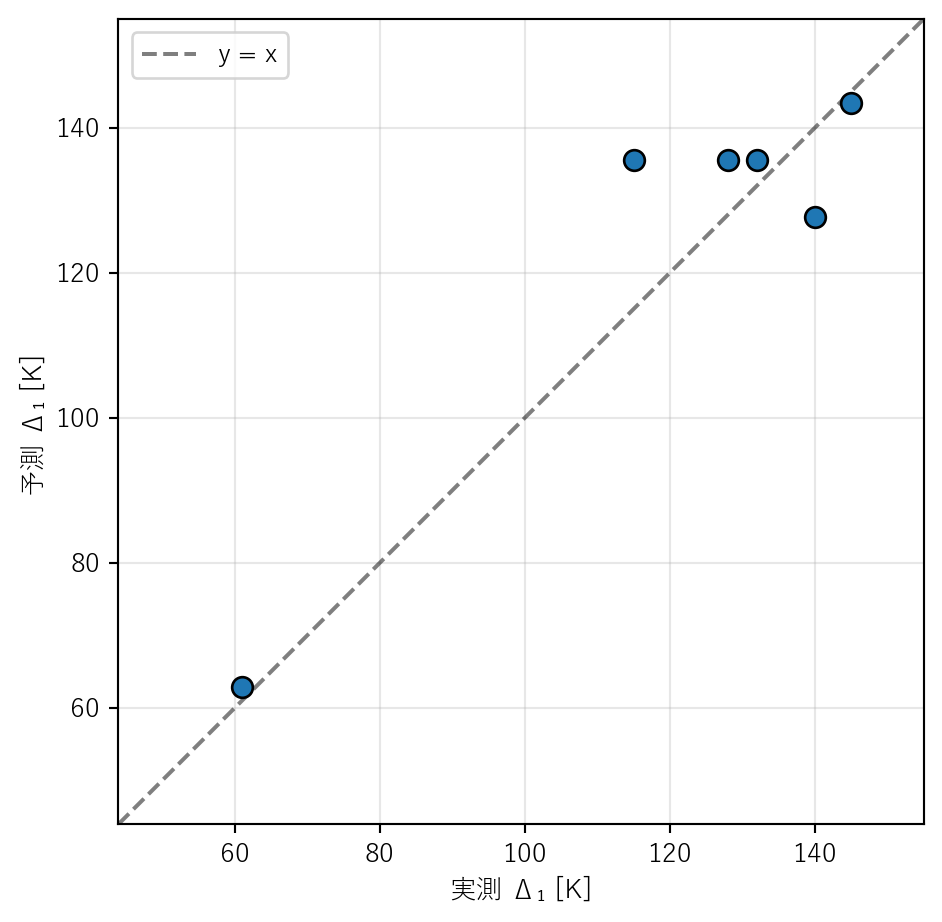
parity plot
予測値 vs 実測値のプロット(parity plot)は、論文の Fig. 2(a) に対応する。
コード
= plt.subplots(figsize= (5 , 5 ))= 60 , edgecolors= "k" , zorder= 3 )= [min (y.min (), y_pred_test.min ()) - 10 , max (y.max (), y_pred_test.max ()) + 10 ]"k--" , alpha= 0.5 , label= "y = x" )"実測 Δ₁ [K]" )"予測 Δ₁ [K]" )"equal" )True , alpha= 0.3 )
4.4 多変量回帰へ広げる
半径だけではなく、4記述子、さらに A/B サイト分離版を試す。
コード
# 3つのモデルを比較するための準備 = [c for c in feat_cols if c.startswith("B_" )]= [c for c in feat_cols if c.startswith("A_" )]= ["半径のみ" , ["B_Ion_Radius" ]),"B サイト 4記述子" , b_cols),"A/B 分離 8記述子" , feat_cols),# 同じ split で比較(公平な比較のため) = []for name, cols in configs:= df[cols].values= train_test_split(= 0.33 , random_state= 42 = LinearRegression().fit(X_tr, y_tr)= m.predict(X_tr)= m.predict(X_te)"モデル" : name,"特徴量数" : len (cols),"train RMSE" : f" { np. sqrt(mean_squared_error(y_tr, y_p_tr)):.1f} " ,"test RMSE" : f" { np. sqrt(mean_squared_error(y_te, y_p_te)):.1f} " ,"train R²" : f" { r2_score(y_tr, y_p_tr):.3f} " ,"test R²" : f" { r2_score(y_te, y_p_te):.3f} " ,
0
半径のみ
1
8.7
10.4
0.905
0.863
1
B サイト 4記述子
4
7.2
9.4
0.935
0.889
2
A/B 分離 8記述子
8
6.3
5.2
0.949
0.966
特徴量を増やすと train の性能はどう変化するか
test の性能は必ず改善するか。そうでないなら、なぜか
データ数(18点)に対して特徴量数(8)は多いか少ないか
特徴量を増やすと train RMSE は下がる(= train は良くなる)。自由度が増えて学習データに合わせやすくなるため
test は必ずしも改善しない。データ数に対して特徴量が多すぎると、学習データの偶然のパターンまで拾ってしまい(過学習)、未知データへの汎化性能が落ちる
18点に対して8特徴量は多い。経験則として、特徴量1つあたり最低5〜10点のデータが望ましい。8特徴量なら40〜80点は欲しいところだが、18点しかない
4.5 split の不安定さと交差検証
18組成しかないデータで train/test split を1回だけ行うと、どの点が test に入るかで結果が大きく変わる 。
コード
# random_state を変えて結果の揺れを見る print ("random_state による評価の揺れ(半径のみモデル):" )print (f" { 'seed' :>5} { 'test RMSE' :>10} { 'test R²' :>8} " )print ("-" * 30 )for seed in [0 , 1 , 42 , 99 , 123 ]:= train_test_split("B_Ion_Radius" ]].values, y,= 0.33 , random_state= seed= LinearRegression().fit(X_tr, y_tr)= np.sqrt(mean_squared_error(y_te, m.predict(X_te)))= r2_score(y_te, m.predict(X_te))print (f" { seed:>5} { rmse:>10.1f} { r2:>8.3f} " )
random_state による評価の揺れ(半径のみモデル):
seed test RMSE test R²
------------------------------
0 9.4 0.337
1 11.9 0.798
42 10.4 0.863
99 11.4 0.861
123 11.6 0.467
RMSE が seed によって大きく変動することが確認できる。単一 split の評価は信用できない 。
この問題を解決するのが 交差検証(cross-validation; CV) である。論文では 3-fold CV を採用している。
コード
from sklearn.model_selection import KFold, cross_validatedef evaluate_cv(X, y, model, n_splits= 3 ):"""3-fold CV で RMSE と R² を計算する""" = KFold(n_splits= n_splits, shuffle= True , random_state= 42 )= cross_validate(= cv,= {"rmse" : "neg_root_mean_squared_error" , "r2" : "r2" },= True ,return {"train RMSE" : f" { - scores['train_rmse' ]. mean():.1f} ± { scores['train_rmse' ]. std():.1f} " ,"test RMSE" : f" { - scores['test_rmse' ]. mean():.1f} ± { scores['test_rmse' ]. std():.1f} " ,"train R²" : f" { scores['train_r2' ]. mean():.3f} ± { scores['train_r2' ]. std():.3f} " ,"test R²" : f" { scores['test_r2' ]. mean():.3f} ± { scores['test_r2' ]. std():.3f} " ,
コード
# 3つのモデルを 3-fold CV で比較 = []for name, cols in configs:= df[cols].values= evaluate_cv(X_c, y, LinearRegression())"モデル" : name, "特徴量数" : len (cols), ** res})
0
半径のみ
1
9.0 ± 0.7
10.0 ± 0.9
0.893 ± 0.010
0.834 ± 0.029
1
B サイト 4記述子
4
6.5 ± 1.0
10.5 ± 2.0
0.945 ± 0.008
0.816 ± 0.052
2
A/B 分離 8記述子
8
4.7 ± 2.1
7.7 ± 3.6
0.968 ± 0.019
0.896 ± 0.075
CV では各 fold の結果を平均 ± 標準偏差で報告する。4.2 節の DummyRegressor(R² = 0)と比べれば、半径1変数でも明確な改善が見られる。特徴量を増やすと train 性能は上がるが、test の改善幅は頭打ちになる傾向に注目してほしい。
論文でも「RMSE = 7.21 ± 1.18 K, R² = 0.907 ± 0.049」と同じ形式で報告されている。ただし論文の値は、物理ベースラインと GPR を組み合わせたフルモデルの結果であり、ここでの単純な線形回帰とは異なる。
機械学習の性能は、学習に使わなかったデータ で測らなければ意味がない。小標本データでは単一 split の結果は不安定であり、交差検証で揺れをならす必要がある。
4.6 わざと失敗する:データリーク
ここで、やってはいけないコード を実際に書いて、何が問題かを確認する。
悪い例:split 前に前処理を fit する
コード
from sklearn.preprocessing import StandardScalerfrom sklearn.impute import SimpleImputer= df[feat_cols].values.copy()# ❌ 全データで imputer と scaler を fit してから split = SimpleImputer(strategy= "mean" )= StandardScaler()= imp_bad.fit_transform(X_all) # ← 全データを見ている = scaler_bad.fit_transform(X_bad) # ← 全データを見ている = train_test_split(= 0.33 , random_state= 42 = LinearRegression().fit(X_tr, y_tr)= np.sqrt(mean_squared_error(y_te, m_bad.predict(X_te)))print (f"悪い例の test RMSE: { rmse_bad:.1f} K" )
このコードでは、scaler の平均と標準偏差の計算に test データの情報が混入 している。これが データリーク (data leakage)である。
論文では、3-fold CV の各 fold で、ベースラインの fit、欠損補完、標準化をすべて training fold のみで行っている。test fold の情報は一切使わない。この作法が、18組成という小標本での信頼性を支えている。
良い例:Pipeline で前処理とモデルを一体化する
コード
from sklearn.pipeline import Pipeline= Pipeline(["imputer" , SimpleImputer(strategy= "mean" )),"scaler" , StandardScaler()),"model" , LinearRegression()),= KFold(n_splits= 3 , shuffle= True , random_state= 42 )= cross_validate(= cv,= {"rmse" : "neg_root_mean_squared_error" , "r2" : "r2" },= - scores["test_rmse" ].mean()= scores["test_r2" ].mean()print (f"良い例の test RMSE: { rmse_good:.1f} ± { - scores['test_rmse' ]. std():.1f} K" )print (f"良い例の test R²: { r2_good:.3f} ± { scores['test_r2' ]. std():.3f} " )
良い例の test RMSE: 7.7 ± -3.4 K
良い例の test R²: 0.895 ± 0.072
Pipeline を使うと、cross_validate が各 fold で自動的に imputer と scaler を training fold だけで fit し、test fold には transform のみを適用する。前処理もモデルの一部 であり、評価ループの外に置いてはならない。
以下のコードにデータリークがあるか判定し、ある場合はどこが問題かを指摘せよ。
= StandardScaler()= scaler.fit_transform(X)= cross_validate(model, X_scaled, y, cv= 3 )
リークがある。scaler.fit_transform(X) が CV ループの外 で全データに対して実行されている。各 fold の test データの統計量(平均・標準偏差)が scaler に混入しているため、test 性能が実際より良く見えうる。正しくは、Pipeline の中に scaler を入れて cross_validate に渡すべきである。
線形回帰では、scaler のリークによる数値差が小さいことがある。しかし、これは「リークしても問題ない」のではなく、「たまたま影響が見えにくい」だけである。GPR やカーネル法では、scaler のリークが結果に大きく影響する。正しい作法を最初から身につけておくべきである。
4.7 次章への見通し:なぜ GPR か
ここまでの線形回帰では、予測値は1つの数字 として返される。「この組成の \(\Delta_1\) は 90 K です」とは言えるが、「その予測をどれだけ信用してよいか」は分からない。
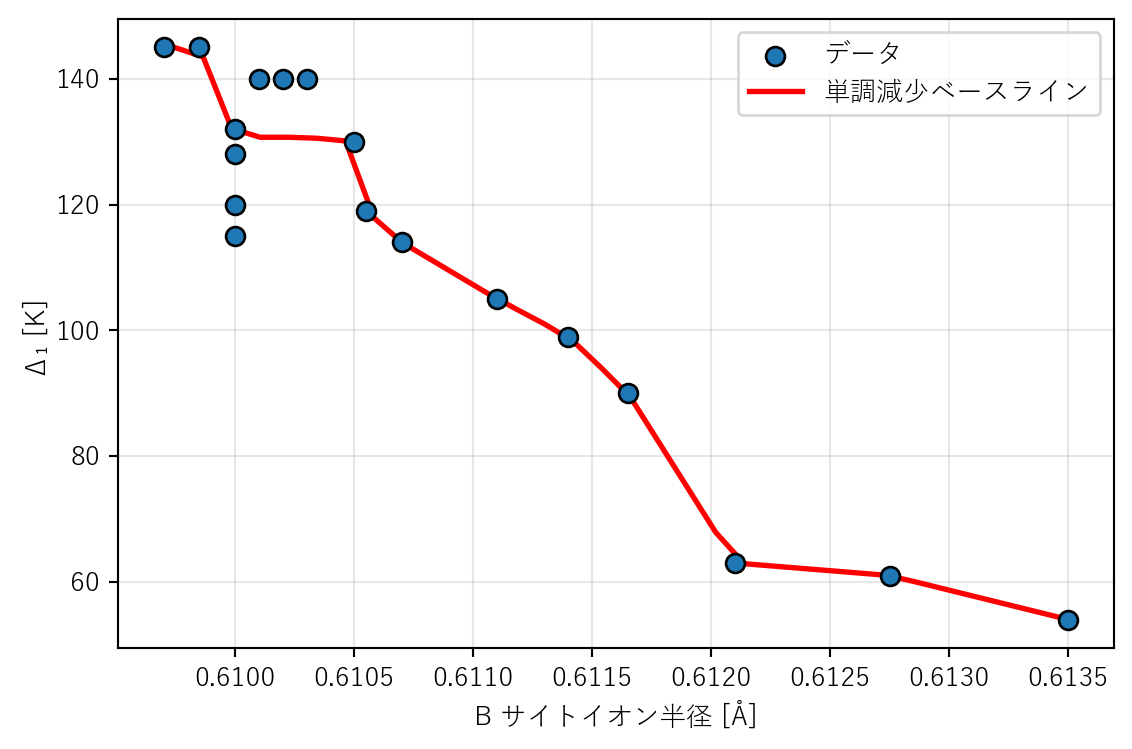
散布図に戻ると、B サイト半径と \(\Delta_1\) の関係はおおまかに単調減少だが、直線では捉えきれない曲がりがある。論文では、この関係をまず 単調減少ベースライン (IsotonicRegression)で捉え、その 残差 を GPR で学習する。
コード
from sklearn.isotonic import IsotonicRegression= df["B_Ion_Radius" ].values= IsotonicRegression(increasing= False )= np.linspace(X_rb.min () - 0.01 , X_rb.max () + 0.01 , 200 )= iso.predict(x_grid)= plt.subplots(figsize= (6 , 4 ))= 50 , edgecolors= "k" , zorder= 3 , label= "データ" )"r-" , linewidth= 2 , label= "単調減少ベースライン" )"B サイトイオン半径 [Å]" )"Δ₁ [K]" )True , alpha= 0.3 )
この単調ベースラインは「半径が大きくなるほど \(\Delta_1\) は下がる(または変わらない)」という物理的制約を反映している。直線回帰よりも物理に近い。
次章では、このベースラインの上に GPR を重ねることで、予測値だけでなく 予測の不確かさ \(\sigma\) を得る方法を学ぶ。そして、\(\sigma\) を使って「この候補は信用してよいか」を判断する——材料探索の核心に踏み込む。
まず DummyRegressor で「平均を答えるだけ」の基準(R² = 0)を定め、次に半径の単回帰で改善幅を CV で測り、以上から「半径だけでも予測の方向は正しいが、データ数に対して特徴量を増やすと過学習のリスクが伴う」と結論づけられる。前処理もモデルの一部であり、評価の外に置いてはいけない。単純モデルは弱いのではなく基準 であり、基準から一段ずつ改善する——それが論文の実践した ML の作法である。
章末演習
演習 4-1 本章で比較した3つの線形回帰モデル(半径のみ / B サイト4記述子 / A/B 分離8記述子)の CV 結果を表にまとめ、どのモデルが最も信頼できるか、理由とともに述べよ。
演習 4-2 RMSE と R² の違いを、材料研究者の立場から150字以内で説明せよ。ヒント: 単位と基準に注目せよ。
演習 4-3 以下の前処理コードにデータリークがあるかを判定し、修正せよ。
= df[feature_cols].values= df["delta_1" ].values= SimpleImputer(strategy= "mean" ).fit_transform(X)= StandardScaler().fit_transform(X)= train_test_split(X, y, test_size= 0.33 )= LinearRegression().fit(X_train, y_train)演習 4-4 論文は「RMSE = 7.21 ± 1.18 K, R² = 0.907 ± 0.049」と報告している。本章の線形回帰の CV 結果と比較し、論文モデルがどの程度優れているか論じよ。なぜそこまで差が出るのか、1〜2文で理由を推測せよ。