block-beta
columns 2
block:desk:2
columns 2
A["常時ルール<br>(Layer A)"]:1
B["ロード済みスキル<br>(Layer B)"]:1
C["会話履歴"]:2
D["読んだファイルの内容"]:1
E["コマンドの出力"]:1
end
style desk fill:#f8f9fa,stroke:#333,stroke-width:2px
style A fill:#d4edda,stroke:#28a745
style B fill:#fff3cd,stroke:#ffc107
style C fill:#d1ecf1,stroke:#17a2b8
style D fill:#d1ecf1,stroke:#17a2b8
style E fill:#d1ecf1,stroke:#17a2b8
第6章 AIは忘れる――文脈と要約の設計
6.1 導入:長い実験ノートの読みにくさ
ある学生が、3週間にわたる実験の記録を1冊のノートにつけた。電子天秤の読み値、温度計の変動、うまくいかなかった試行、途中で変えた手順、TA との相談内容、雑談の断片——すべてが時系列で書き連ねてある。80ページに達したノートを翌週開いたとき、「先週どこまで進んだか」を把握するのに30分かかった。
一方、別の学生は同じ実験をしていたが、毎週末に1ページの要約を書いていた。「目的」「今週の到達点」「決まった方針」「未解決の問題」「来週やること」の5項目を箇条書きにしただけである。翌週、この学生は要約を30秒で読み、すぐに作業を再開できた。
両者の違いは記憶力ではない。情報の整理の仕方である。
AI にも同じ問題が起きる。第5章で、知識を「常時知識」「オンデマンド知識」「会話文脈」の3層に分けた。本章で扱うのは、3層目の会話文脈(Layer C)の問題である。作業が長くなると、やり取りの蓄積で文脈が溢れ、重要な情報がノイズの中に埋もれる。AI が「忘れる」ように見えるのは、正確には、必要な情報が大量の不要な情報に埋もれて参照できなくなる現象である。
この問題に設計でどう対処するか。それが本章の主題である。
6.2 文脈には何が入るか
まず、AI の「作業机」に何が載っているかを確認する。
第5章では「作業机の上にあるもの全部」と説明した。もう少し具体的に中身を見ると、次の要素が含まれている。
ここで重要な気づきがある。文脈は「会話のログ」だけではない。ファイルの内容、コマンドの出力結果、読み込まれたスキル、常時ルール——これらがすべて同じ作業机の上に載っている。作業を進めるほど、読んだファイルや試したコマンドの結果が積み上がり、机の上はどんどん狭くなる。
第6章は、AI の「記憶力」の章ではない。作業空間の整理術の章である。
6.3 文脈はなぜ溢れるか
AI の作業机には広さの限界がある。この広さをトークンという単位で測る。トークンとは、AI が情報を処理する際の分量の単位であり、おおむね「日本語1文字≒1〜2トークン」「英語1単語≈1トークン」と考えてよい(厳密な定義は本書の範囲外であり、ここでは分量の目安として使う)。
作業机の広さに上限がある以上、何がどれだけの場所を占めるかを見積もることが重要である。ここで大切なのは、まず見積もることである。
文脈の使用量は、おおよそ次の式で表される。
\[ \begin{aligned} \text{使用量} \approx\; & \underbrace{\sum \text{会話ターン}}_{\text{可変}} + \underbrace{\sum \text{読んだファイル}}_{\text{可変}} + \underbrace{\sum \text{コマンド出力}}_{\text{可変}} \\ &+ \underbrace{\text{ルール}}_{\text{固定}} + \underbrace{\text{ロード済みスキル}}_{\text{固定}} \end{aligned} \tag{1}\]
右辺の最後の2項(ルール、ロード済みスキル)は、セッションの最初に決まる固定コストである。一方、最初の3項(会話、ファイル、コマンド出力)は作業の進行に伴って増え続ける可変コストである。
具体的な数字で感覚をつかむ。1000行のソースコードを読むと、おおよそ4000トークンを消費する。30個のファイルを読み、20回コマンドを実行すれば、それだけで10万トークンを超える。作業机の広さが有限である以上、この勢いで積み上がれば、いずれ溢れる。
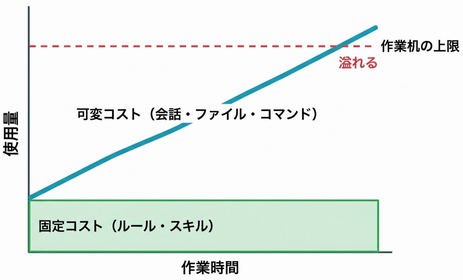
この図が示しているのは、固定コスト(ルールとスキル)は水平線で、可変コスト(会話・ファイル・コマンド)は右肩上がりの線である。長い作業ほど可変コストが支配的になり、やがて上限に達する。
式 1 から、対処法は2つに分類される。
- 固定コストを減らす:不要なルールを削る、スキルをオンデマンド化する(第5章で設計済み)
- 可変コストを抑える:蓄積した情報を圧縮する、外部に出す(本章の主題)
6.4 文脈圧縮の3層戦略
可変コストの増加に対処するために、3つの層で段階的に圧縮する戦略がある。
block-beta columns 1 L1["<b>Layer 1:細部の簡略化</b><br>古い作業の詳細を痕跡だけに置き換える<br>例:「ファイルAを読んだ」→ 内容は消し、読んだ事実だけ残す"]:1 L2["<b>Layer 2:全体の要約</b><br>会話全体を要点にまとめ直す<br>例:80ページのノート → 1ページの要約"]:1 L3["<b>Layer 3:明示的な整理</b><br>作業の節目で、意図的に整理のタイミングを作る<br>例:「ここまでの進捗を整理しよう」"]:1 style L1 fill:#d4edda,stroke:#28a745 style L2 fill:#fff3cd,stroke:#ffc107 style L3 fill:#f8d7da,stroke:#dc3545
Layer 1:細部の簡略化
最も軽い圧縮である。以前読んだファイルの全文や、以前実行したコマンドの出力全文を、「読んだ」「実行した」という痕跡だけに置き換える。情報そのものは失われるが、「何をしたか」の記録は残る。
実験ノートの比喩では、「3時間かけて温度を15分ごとに記録したデータ表」を「温度データ取得済み、12:00〜15:00、5℃〜25℃の範囲」に圧縮するようなものである。元データは別の場所(ファイル)に残っており、必要なら再度読み込める。
Layer 2:全体の要約
Layer 1 で足りなければ、会話全体を要約に置き換える。80ページの実験ノートを1ページの要約にまとめるのと同じ発想である。会話の詳細は失われるが、「何を目指しているか」「何が決まったか」「何が未解決か」が残る。
Layer 3:明示的な整理
Layer 1 と Layer 2 は、作業机が溢れそうになったときに自動的に起きる圧縮である。Layer 3 は、それとは別に、作業者が意図的に整理のタイミングを作ることである。「ここまでの進捗を整理しよう」と宣言し、要約を作り、不要な情報を片付ける。
物理実験で言えば、「今日の実験が終わったら、ノートの最後にまとめを書く」という習慣に相当する。自動圧縮に任せるだけでなく、節目で意識的に整理することで、情報の質を保てる。
3つの層を日常の言葉でまとめると、こうなる。
- 細かいログは痕跡だけ残す(Layer 1)
- 会話全体は節目で要点化する(Layer 2)
- 必要なら自分で整理タイミングを作る(Layer 3)
6.5 良い要約と悪い要約
Layer 2 と Layer 3 で要約を作るとき、「短くすればよい」というわけではない。何を残し、何を捨てるかの設計が要約の質を決める。
良い要約と悪い要約を比較する。
| 観点 | 悪い要約 | 良い要約 |
|---|---|---|
| 目的 | 書かれていない | 「比熱の測定実験。水と金属の温度変化を比較する」 |
| 決まった方針 | 書かれていない | 「チタンとアルミの2種類で測定。水量は200ml で統一」 |
| 変更した箇所 | 書かれていない | 「温度計を非接触式に変更(接触式は応答が遅いため)」 |
| 未解決の問題 | 書かれていない | 「アルミの測定値が理論値より15%高い。放熱の影響か」 |
| 次にやること | 書かれていない | 「断熱材を追加して再測定する」 |
| 全体の印象 | 「いろいろやった」 | 「何がどこまで進み、何が残っているか」が30秒でわかる |
良い要約に含まれるべき5項目を取り出す。
- 目的:何をしようとしているか
- 決定事項:何が決まったか
- 変更の記録:何を変えたか、なぜ変えたか
- 未解決の問題:何がまだ片付いていないか
- 次の一手:次に何をすべきか
この5項目が揃っていれば、要約を読んだだけで作業を再開できる。逆に、これらが抜けている要約は、「短い」だけで役に立たない。
要約とは「短くすること」ではない。重要な状態を保ったまま、不要な詳細を捨てる再配置である。
6.6 文脈を軽く保つ他の方法
圧縮だけが文脈管理の手段ではない。そもそも文脈が溢れにくい設計を最初から行うことも有効である。
方法1:セッションを分ける
1つの長大な会話で全部をやろうとするのではなく、仕事の区切りでセッションを分ける。レポートの「文献調査」と「本文執筆」を別のセッションにすれば、文献調査の詳細が本文執筆の文脈を圧迫しない。
方法2:スキルをオンデマンドにする(第5章の復習)
第5章で設計した通り、常時ロードする知識を最小限にし、スキルは必要なときだけ読み込む。これは 式 1 の固定コストを減らす方法である。
方法3:別の担当に調査を任せる(第7章の予告)
長い調査を AI 自身がすべて行うと、調査結果がそのまま文脈に積み上がる。しかし、調査を別の担当(サブエージェント)に任せ、結果の要約だけを受け取れば、主な作業の文脈は軽く保てる。これは第7章で詳しく扱う。
方法4:永続ルールを会話の外に出す
会話の中で「次からはこうしよう」と決めたルールは、そのまま会話に埋もれていると、圧縮のときに消えてしまう可能性がある。重要なルールは、会話文脈ではなく常時知識(常駐ルールファイル)に書き出すべきである。
ノート大事なことは「思い出してもらう」のではなく、消えにくい場所へ移す
AI に「さっき言ったことを覚えて」と頼むのは、会話文脈に依存している。会話が圧縮されれば消える。大事なルールや方針は、会話の外——常時知識やスキル——に書き出す。消えにくい場所に情報を配置することが、「忘れさせない」設計の本質である。
この方法4は、第5章で学んだ知識の3層モデルと直結している。
| 情報の性質 | 置くべき場所 | 理由 |
|---|---|---|
| いつも守るルール | 常時知識(常駐ルールファイル) | 圧縮で消えない |
| ときどき必要な手順 | スキル(Layer B) | 必要時だけ読み込む |
| 今回の進捗・決定 | 会話の要約 | 圧縮時に5項目を残す |
6.7 第7章への橋渡し
本章で、単独の AI が長い仕事を安定して進めるための設計が一通り揃った。ここまでの道のりを振り返る。
- 第1章:AI を「系」として見る視点
- 第2章:エージェントループ(思考→道具→確認の繰り返し)
- 第3章:道具の設計(何を持たせ、何を持たせないか)
- 第4章:計画の設計(ToDo 板で状態を管理する)
- 第5章:知識の設計(常時知識とオンデマンド知識を分ける)
- 第6章:文脈の設計(長い仕事の情報を圧縮・整理する)
ここまでは、1つの AI が単独で仕事をする前提であった。
しかし、仕事が大きくなると、1つの AI がすべてを抱えるのは効率が悪い。調査に時間をかけると文脈が膨らむ(6.3節)。複数の専門分野にまたがる仕事では、1つの文脈に全部を入れると混乱する。
そこで次の疑問が生まれる。仕事を分担できないか。
次の第7章では、「役割分担した別の担当」——サブエージェント——の設計を扱う。1つの AI が全部をやるのではなく、調査担当・要約担当・点検担当を分け、それぞれが独立した作業机で働く仕組みである。
演習:長い会話を、次に使える要約へ変換する
形式:3〜4人1組、30分
準備:教員は、あえて冗長な「AI との長いやり取り例」を配布する。以下のいずれかを題材にする。
- 実験レポート改善の相談
- プレゼン資料作成の相談
- 文化祭展示準備の相談
この長文には、以下の要素を意図的に混ぜておく。
- 本筋に関係ない雑談
- 途中で却下された案
- 試したが失敗した手順
- 決定された方針
- 未解決の問題
- 次にやるべきこと
手順:
情報を4分類する(15分)
配布された長文を読み、情報を次の4つに分類する。
表 3: 情報の4分類 カテゴリ 説明 例 A. 残すべき重要情報 目的・決定・未解決点 「チタンとアルミで測定すると決めた」 B. 残すが短くしてよい情報 経緯・試行の結果 「3つの方法を比較し、方法Bを採用」 C. 捨ててよい情報 雑談・却下された案の詳細 「昼食の話」「却下した方法Aの詳細手順」 D. 別の場所へ移すべき情報 永続ルール・再利用可能な手順 「表の列幅は統一する」→ 常駐ルールファイルへ 要約を書く(10分)
A4 半ページ以内で、「次回の自分がすぐ再開できる要約」を作成する。6.5節の5項目(目的・決定事項・変更の記録・未解決の問題・次の一手)を含めること。
情報の配置を決める(5分)
分類 D の情報を、以下のどこに置くか決める。
表 4: 情報の配置先 移動先 対応する層 例 常駐ルールファイル 常時知識(Layer A) 「表の列幅は統一する」 スキル オンデマンド知識(Layer B) 「グラフ作成の手順」 要約メモ 会話文脈の圧縮結果 「今回の進捗と次の一手」
振り返りの問い:
- 「捨ててよい」と判断したもののうち、迷ったものはあるか。判断基準は何だったか
- 要約を書くとき、何を残すのが一番難しかったか
- 「別の場所へ移すべき情報」は、会話に残しておいたら何が起きるか
章末課題
課題:自分の長い課題を「再開しやすい状態」に設計する
今学期の課題や研究活動の中から、数日以上にまたがる作業を1つ選ぶ。
想定する作業の例:
- 実験レポートの執筆(データ整理→考察→本文→校正)
- 発表準備(文献調査→構成決め→スライド作成→リハーサル)
- 卒研の先行研究調査(論文検索→読解→整理→要約)
- インターン応募準備(自己分析→企業調査→書類作成→面接対策)
必須項目:
情報の一覧と分類表:その作業で増えていきそうな情報を列挙し、以下の3種類に分類する
- 毎回必要な情報(常時知識)
- 必要時だけ必要な情報(スキル)
- 今回だけ必要な情報(会話文脈)
圧縮時に残す情報の設計:文脈が溢れて圧縮が必要になったとき、何を残すべきかを明示する
再開用の要約文(300〜500字):作業の途中で中断し、翌日再開するとして、次の5項目を含む要約を書く
- 目的
- 現在の到達点
- 決まった方針
- 未解決の問題
- 次の一手
情報の配置設計:「会話の中に残す情報」「常時知識に移す情報」「スキルに移す情報」をそれぞれ挙げ、なぜその配置にしたかを説明する
提出形式:A4 1〜2枚
評価観点:
- 情報の分類が適切か(常時知識・スキル・会話文脈の区別が明確か)
- 要約が6.5節の5項目を含み、再開可能な形になっているか
- 常時知識・スキル・会話要約の役割分担ができているか
- 「忘れさせない工夫」ではなく「埋もれさせない工夫」として設計されているか
- 第5章(知識管理)の課題と整合しているか
第6章のまとめ
本章では、長い仕事で文脈が溢れる問題と、それに対処する設計を学んだ。
要点を整理する。
- AI の文脈(作業机)には、会話履歴・読んだファイル・コマンド出力・ルール・スキルが載っている。作業が長くなると、可変コストの蓄積で上限に達する
- 文脈の使用量は「固定コスト(ルール・スキル)+ 可変コスト(会話・ファイル・コマンド)」で概算できる。長い作業ほど可変コストが支配的になる
- 文脈圧縮は3層で行う。細部の簡略化(痕跡だけ残す)→ 全体の要約(節目で要点化)→ 明示的な整理(自分で整理タイミングを作る)
- 良い要約は「短い」だけでなく、目的・決定事項・変更の記録・未解決の問題・次の一手の5項目を含む
- 圧縮以外にも、セッション分割・スキルのオンデマンド化・別担当への委任・永続ルールの外部化で文脈を軽く保てる
- 大事な情報は「思い出してもらう」のではなく、消えにくい場所(常時知識やスキル)に移す
ここまでの6章で、単独の AI を安定して働かせる設計が一通り揃った。次の第7章からは、複数の AI が役割分担して働く設計に進む。1つの AI が全部を抱えるのではなく、調査・要約・点検を別の担当に分ける——そのための仕組みを学ぶ。