前回に引き続き、高専2年生のホームルームクラスを対象に、Pythonプログラミングとデータ分析の実践的な授業を行いました。今回は、クラスタリング分析という手法を用いて、大谷翔平選手の投球データを分析する課題に取り組みました。
クラスタリング分析は、似たような特徴を持つデータを自動的にグループ化する手法であり、データ分析の重要な技術の一つです。授業では、以下の流れで学習を進めました。
- クラスタリングの概要と応用例の説明
- k-meansアルゴリズムの手順の解説
- エルボー法によるクラスタ数の決定方法の説明
- 大谷翔平選手の投球データを用いたクラスタリング分析の実践
以下の動画は、k-meansアルゴリズムがどのようにしてデータをクラスタリングするかを示しています。
k-meansアルゴリズムは、以下のステップを繰り返します。
1. 初期のクラスタ中心をランダムに選択
2. 各データ点を最も近いクラスタ中心に割り当て
3. 割り当てられたデータ点の平均を計算し、新しいクラスタ中心とする
4. クラスタ中心の変化が収束するまで、ステップ2と3を繰り返す
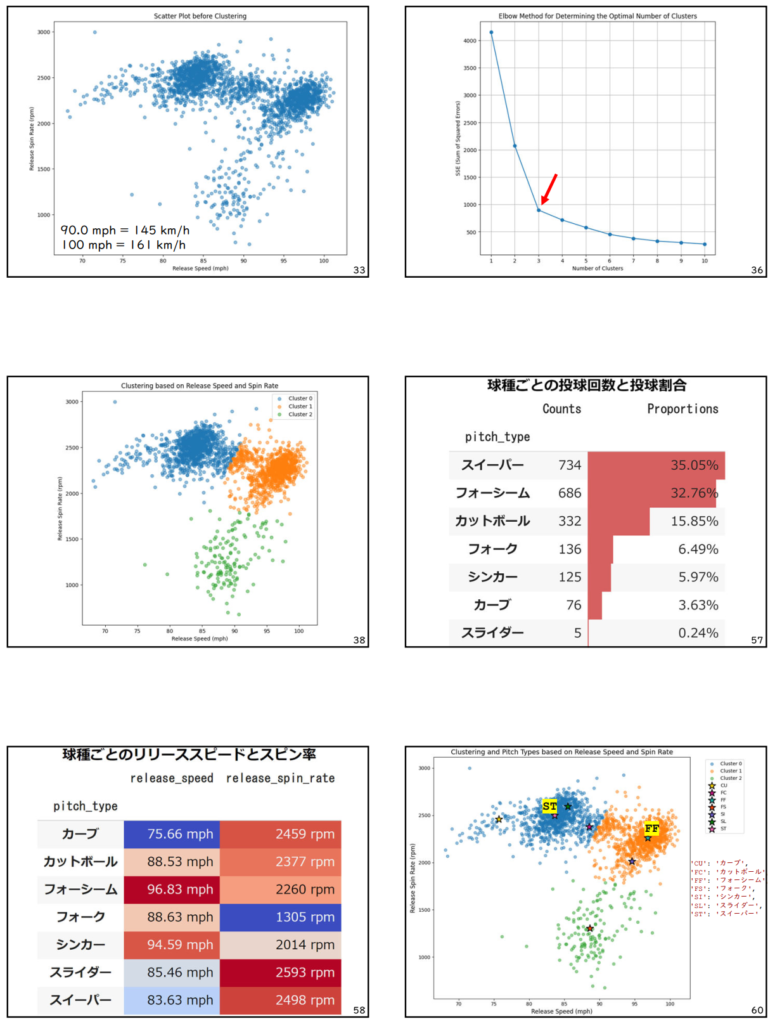
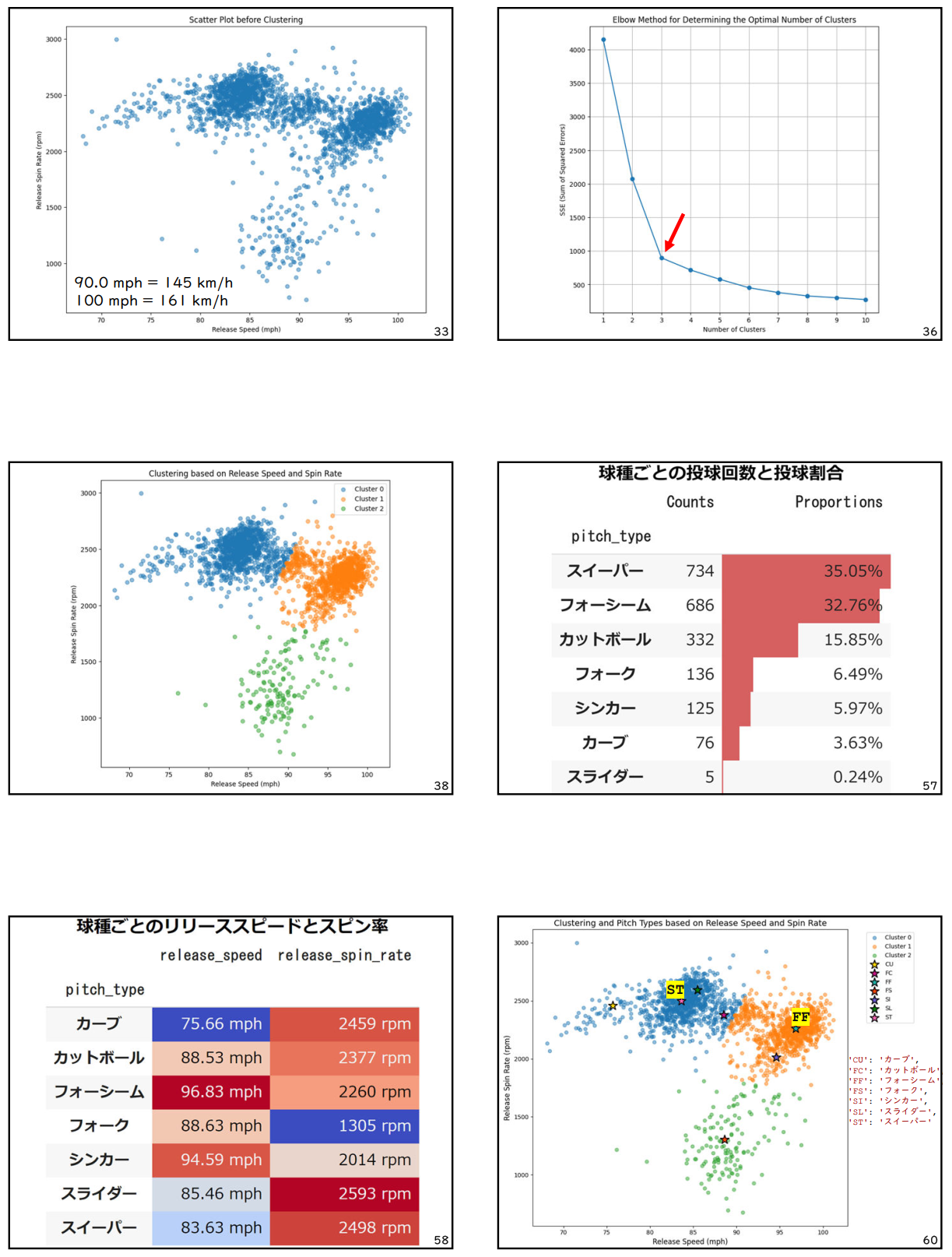
学生たちは、リリーススピードとリリーススピン率の散布図の作成から始め、クラスタリングを実施しました。
クラスタリング分析の結果、大谷翔平選手の投球データは3つのグループに分類されました。さらに、各グループが球種の違いによるものであることが明らかになりました。これにより、学生たちはクラスタリング分析の有用性を実感できたのではないでしょうか。下に示す図は、授業で使用したスライドの一部です。大谷翔平選手の投球データをリリーススピードとリリーススピン率の散布図で表現し、クラスタリングの結果を色分けして示しています。さらに、各グループが主にどの球種で構成されているかを凡例で示すことで、クラスタリングの結果と球種の関連性を明確に表現しました。学生たちはクラスタリング分析の実用性と有用性を直感的に理解することができたと期待しています。
比較的イメージしやすい内容でクラスタリングに取り組みましたが、ソースコードを書き換えて他の選手と比較したり、他のデータと合わせて分析したりと、色々取り組んで欲しいと思います。